Beyond imparting content, the “DASH-Amerikan” project intends to be useful to a wide audience. With the concepts of utility and reproducibility in mind, we’ve made the structure of our digital essay, its style, and the topic models based our textual archive available in a GitHub repository entitled dash-american. We invite you to visit the page and either clone the repository, wholesale, or download key files such as index.html, dashAmerikan.css, and DASHAmerikan.js, so you can adapt them for your own use! In addition to using the Developer Tools in your internet browser (found behind the hamburger button on a PC or the triple dots on a Mac), the files for markup language (HTML), Cascading Style Sheets (CSS), and JavaScript (.js) can provide a baseline for reproducing features from our digital essay such as the black navigation bar, cycling image banner, footnotes, kiss icons, image grid, and the button that shares our site on Twitter. Each design element is built to be borrowed, and beginners may find it useful to identity key lines in their text editor that correspond to the layout and formatting of header, footer, body text, and incorporating Google Fonts.
As described in our essay (Cf. the second paragraph of “distant reading the kardashians”), the process of creating “DASH-Amerikan” occurred in three (non-distinct) phases: webscraping, topic modeling, and the authorship and design of the digital essay. In listing our process, we do not mean to say that the experience was sequential. It was not! In fact, we were constantly waffling between so-called “steps”—returning, revisiting, and revising even as we made progress towards our ultimate goal. The tools we used to scrape and analyze text from Hulu, Twitter, Us Weekly, and Wattpad can be found via hyperlinks in our main page, but can also be listed here as a kind of “study guide” for producing a project like our own. Key sites for reference include:
-- The open source software CCExtractor (use: to scrape text from Hulu);
the statistical computing language R and the package rtweet;
-- Tom Dickinson’s Twitter scraper (use: to apply to individual family accounts);
-- Beautiful Soup's package for parsing XML (use: to extract text from an Us Weekly archive with tags to articles about the Kardashians);
-- a scraping tool we built for the fanfiction site Wattpad (use: to collect stories about the Kardashians);
-- and the topic modeling software MALLET (use: to analyze our archive).
Some of these tools require familiarity with the programming language Python, and a useful tutorial on “Getting Started with Topic Modeling and MALLET” by Shawn Graham, Scott Weingart, and Ian Milligan can be found here. It should be noted, however, that none of the members of the 2016/17 Praxis cohort came into the project with much experience using any of these languages or tools. We made it work with a lot of support from the Scholars’ Lab staff at the University of Virginia, constant Googling, and scrolling through issues on Stack Overflow! What follows is an extended narrative of how we collected and cleaned various Kardashian archives, which we produce here to serve as a full listing of our materials as well as to provide information on best practices for these data types.
We gathered closed captioning transcripts for 11 seasons of the flagship Kardashian reality television show, Keeping Up with the Kardashians. To do so, we used the open-source software CCExtractor and the video streaming site Hulu. CCExtractor gave us works with two file types, .srt and .vtt. The .srt files are created by running optical character recognition on video subtitles, much the same way other “OCR” software scans and saves text files from scans of printed pages. The more reliable .vtt format, on the other hand, is a web standard for closed caption files that can be downloaded directly as it is meant to be retrieved by the browser and then displayed on top of streaming video. Both file types have a similar format, however, where the text from the captions is displayed beside a timestamp for the video and the name of the line’s speaker.
We took a number of approaches to data mining Twitter. Our first efforts used the statistical computing language R, and the package rtweet. This gave us relatively easy to use access to Twitter’s streaming API (Application Program Interface), allowing us to retrieve recent tweets around keywords related to the Kardashians and even a certain number of tweets from the accounts themselves. While rtweet and the streaming API affords us useful tools for retrieving data on events (for example trending topics) in real time, it was quite limited as a tool for archiving older tweets. It was particularly useful in becoming acquainted with the formatting and metadata associated with tweets downloaded in the JSON file format.
It soon became clear, however, that we would need to delve further into the Twitter archive to explore the data we were most interested in around the Kardashians. We noticed that we could circumvent the streaming API’s limitations by viewing old tweets with Twitter’s advanced search function. Using the browser, it was simple to display tweets by user, hashtag, and most importantly, timestamp range dating back to the beginnings of Twitter. While this was an unsuitably halting way to explore very old tweets, it provided us with proof of concept at least; Twitter’s own tools for searching through tweets could be used to find whatever archives we would ultimately settle on. After some diligent Googling, we came across Tom Dickinson’s writeup of Twitter-scraping with Python using the advanced search feature. Dickinson's code was quite easy to adapt for our purposes, and in short order we were able to gather the complete Twitter archive of the relevant Kardashians. The script works by constructing a URL from fields that the user inputs (username, tweet text, date range etc.) and scraping tweets into JSON files using the Python library Beautiful Soup. The script is even quite speedy; by using “multithreading” to access the relevant tweets through multiple parallel queries to the page, it is capable of retrieving many thousands of tweets a minute. All that remained was to combine the JSON files representing each thread in the command line.
Like our Twitter scraping tool, our Us Weekly article scraper used Python’s Beautiful Soup library. To gather our Kardashian article cache, we navigated to the page which listed all articles with the Kardashian tag. Using Beautiful Soup’s HTML parser, our script automatically retrieved the headline and URL of each article, creating a CSV file with the article titles and location. This file was then used to open each URL and download the contents of the article. This way, we would have a file indexing the major topics covered by Us Weekly alongside the full text of the articles, which we would later use in our topic modeling analysis.
Using the Flask micro-framework for Python we built an application that would allow us to access Wattpad's API. This allowed us to gain access to Wattpad and search the website for relevant stories. The API documentation that was most relevant to our interests were Wattpad's "categories," "lists," and "stories." After manually identifying all possible Kardashian search terms, we ran these terms through our application. As we are most interested in the metadata and commentary produced by fan writers about their work, and not work itself the script produced CSV files that included users, titles, urls, story descriptions, tags, categories, creation date, number of readers, and number of "likes."" From this information, especially the story descriptions and tags, we ran our text analysis.
Part of the difficulty with social media archives is their huge value to corporations for the purposes of targeted advertising and gauging public sentiment. For this reason, platforms like Twitter have a vested interest in keeping the content of tweets locked to some degree within their own system. Nevertheless, Twitter offers certain archival opportunities that other social media platforms do not. While over the lifespan of Twitter, its APIs have been restricted somewhat, they still allow for “streaming” tweets, creating “bot” accounts, and gathering data on retweets, responses, and "likes."" Because the social media data we were interested in present many curatorial problems, we looked to other scholarly organizations that have thought deeply about best archival practices. Documenting the Now, in particular, offered tools that could enable research on Twitter archives while respecting user privacy and abiding by Twitter’s terms of service. Even the best tools require constant maintenance. Our Twitter scraper is currently operational, but it depends on the architecture of Twitter. It constructs URLs according to the way Twitter’s advanced search operates, but those URLs are liable to change at any time. Moreover, Twitter has a vested interest in preventing commercial use of a tool like ours. They sell their own suite of data mining tools as a monthly subscription well beyond what most humanities projects could afford.
For the design our site, we taught ourselves the markup language HTML, CSS, and JavaScript. Our group drew from a few points of inspiration in considering what form our research on the media ecology of the Kardashians would take. Early in our project development, we surveyed digital humanities scholarship we encountered and admired in the past, including essays using online platforms such as Scalar, Digital Humanities Quarterly, and Vectors. The experimental techniques we found allowed us to take some risks of our own, specifically pursuing an interest in projects from popular culture. In particular, we took an extended look at a digital essay by Will Self, entitled “Kafka’s Wound,” that offers a dynamic and surprising look at Franz Kafka’s short story “The Country Doctor” (originally published as Ein Landarzt in 1917).
Our group sought to emulate the essay, in part, because of its use of “Side-note icons,” or image buttons in the margin of the text that revealed additional, multimedia content.1 Our team referred to the icons as the author’s “design element of surprise,” and sought to emulate it with our own kiss icons that are linked to asides that explore some aspect of the Kardashians’ presence in contemporary American culture. Alongside “Kafka’s Wound,” we also took a close look at an essay by Carrie Battan and Glenford Nunez, entitled “Mind Control,” devoted to the singer, songwriter, actress, and model Janelle Monáe that appeared in the online music magazine Pitchfork. The essay’s polished look and the creators’ novel approach to the scrollbar—where navigating up and down makes different visual fields appear, disappear, and produce various effects—pushed our team to design a website that could pass just as easily as promotional content for the Kardashians as it could a piece of scholarly writing.
The most formative influence on the design of our project, however, was the layout of the DASH boutique website:
Our team studied the DASH website, in detail, as well as the brick and mortar stores in West Hollywood and Miami, in detail, in an attempt to pick out their representative features. In the course of our analysis, we came to realize that some of its most distinctive elements are typographic (and are represented, below): the iconic DASH logo; the text within the navigation bar; the division of the site into italicized “featured collections”; and the stark footer with white text on a black background:

Other elements are visual, and involve image buttons that lead deeper into the DASH site. In most cases, these elements are highly modular and appear either as a grid, a row of images, or a rectangular pop-up window that lays on top of the previous content. The cropping (mostly square) and editing of these images (soft and warm) gives the site an aesthetic similar to Instagram, which we also tried to imitate through our own set of curated images:
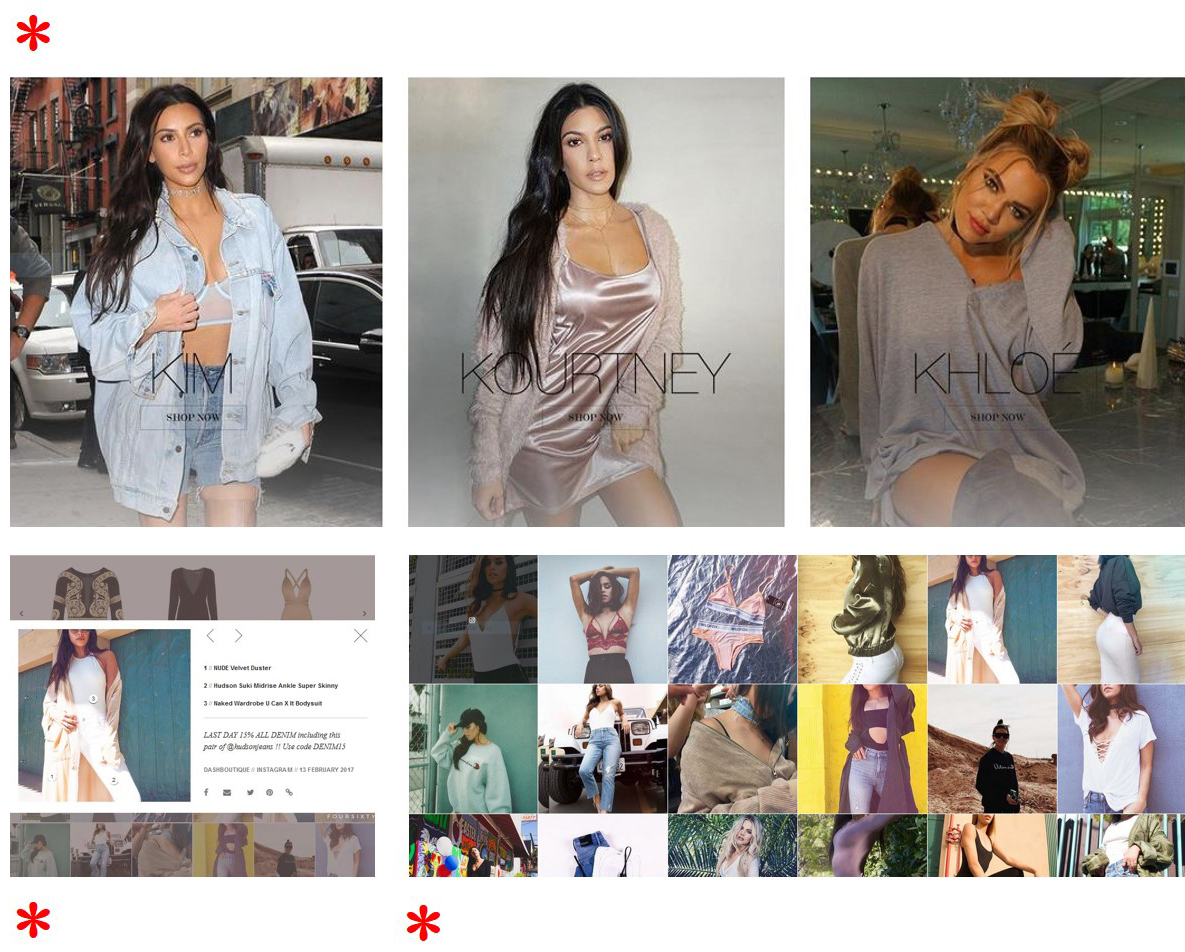
The decision to model the design of our essay after the DASH website is an important aspect of our project, since it shows that we are not merely commenting on the Kardashians, but also being incorporated into the digital pathways around them). As suggested, previously, one of our goals in remaking the DASH website on a server hosted by the University of Virginia is to express, in images, that we are far from disinterested in the Kardashians—in fact, our interest is prolonged, active, and searching. Our facsimile gestures to the fact that we are consumers of the Kardashians, like everyone else, and also our desire to “sell” this project to skeptics who are willing to dismiss the Kardashians as vapid or narcissistic, only. With detractors in mind, we treat the production value of our site as a form of persuasive speech (though, admittedly, one that may not be attractive to those we’d like to reach). As a result, we risk a mild “distancing affect” in our intended audience with the hope that every moment they spend on this site will be the most time they’ve spent thinking about the Kardashians and their impact on American culture. 2